

At the base of every tennis statistic there are Shots; many Shots. And every shot has a multitude of attributes that can be captured.
When I started my Tennis Analytics Integration Platform (AiP) project I was eager to try as many D3 visualizations as possible. Immediately after figuring out how to use the Sunburst chart to create a compact visualization of the Sets, Games, Points and Shots of a Tennis Match, I turned to the Sankey Diagram to try to build a visual filter for selecting Shots to display on a graphic representation of a Tennis Court. I was inspired by the Shot depiction capabilities of ProTracker Tennis. My goal was to build a tool that didn't require checkboxes and which enabled every shot to be seen at once.
Here is the result of my first attempt, using the D3 Sankey plugin and Sankey example created by Mike Bostock.

When applied to the attributes of Shots within a Tennis Match, each attribute becomes a stage where a quantity of Shots is divided or combined; each attribute value becomes a category. In the Sankey diagram above, the attributes from left to right are "Stroke", "Stroke Type", "Trajectory", "Result" and "Endpoint". Hovering over a flow between any two attribute categories reveals the number of Shots within that flow; in other words, which Shots share those two attribute values.

I was quite excited by this early visualization, but it turned out that the re-combining of quantities made it impossible to follow a single Shot as it passed through each stage. In other words, at any one time I was only able to generate a collection of shots that shared the values of two attributes. What was really needed was a way to generate a collection of shots that had the same value for an arbitrary number of attributes. For instance, I wanted to be able to see all Second Serves that were "down the line" or "to the T" Service Winners, or all Backhand CrossCourt Drives that ended in the Net.
Parallel Sets ended up providing me with one possible answer. Parallel Sets were developed circa 2005 by Robert Kosara, Fabian Bendix and Helwig Hauser (see here and here) as a method of visualizing Categorical data. Parallel Sets "divide the flow path" at each stage/attribute; while flows do pass through subsequent stages together, they do not re-combine.

In the parlance of Parallel Sets, each Tennis Shot attribute becomes a "dimension" and each possible attribute value becomes a "category". The dimension "Stroke Type", for example, has the categories "Drive", "Slice", "Lob", "Drop Shot", "Smash", "First Serve" and "Second Serve". Now, admittedly, this looks like a mess of multi-colored spaghetti. Some of the categories have so few Shots in them that they are too narrow to read. Thankfully, each flow or "ribbon" is highlighted as the mouse hovers over it, and a helpful tooltip appears to list each attribute value which applies to the region of the ribbon, between two dimensions, where the mouse is hovering. In the screenshot above the mouse is hovering over a region between Stroke and Stroke Type where the categories are "Serve" and "First Serve". Seventy-one shots match this criteria, which is 79% of all Serves by one player during the match.
The Parallel Sets image above is from the 2015 Western & Southern Open Final between Serena Williams and Simona Halep. You can explore this match yourself here. (Click on either player's name to reveal the Parallel Sets diagram).
The Seventy-one "First Serves" mentioned above are 79% of all Serves by Simona Halep, but this isn't a useful statistic. The real power of the Parallel Sets diagram can be seen by dragging dimensions vertically and categories horizontally to interactively explore the data. By reorganizing the dimensions, in this instance dragging "Stroke Type" to the top of the diagram, it is possible to see that of all "First Serves", 20% were "Serve Winners", 3% were "Aces" and 51% were "In", which totals to 74% (due to rounding the First Serve Percentage given in the Statistics is 73%).



Any number of other statistics can be derived using the above method, but this wan't the original inspiration for making a Parallel Sets diagram part of TAVA. TAVA began with data from ProTracker Tennis and the Parallel Sets "Shot Explorer" initially enabled the visualization of shot placement on a graphic representation of a tennis court:
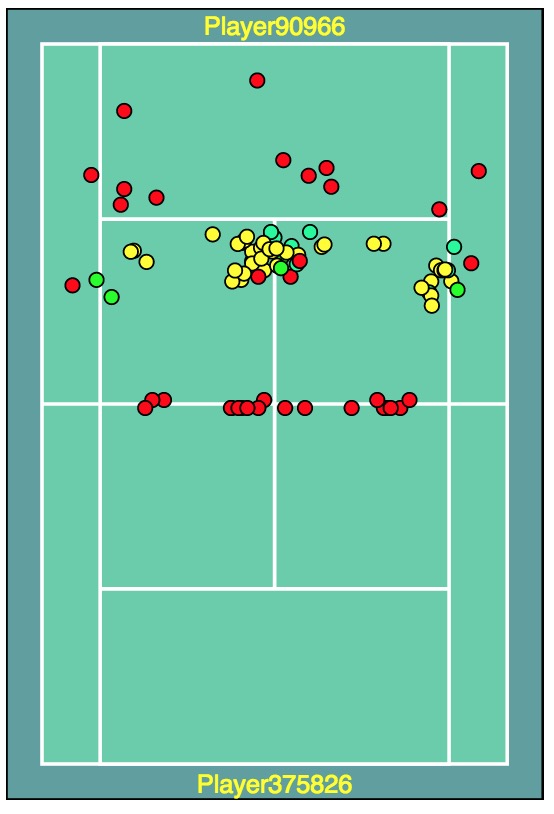


ProTracker Tennis captures coordinate data for first and second serves, the return of serve, and the final "Key Shot" which ends a point, making court visualization possible. When I added support for matches captured by the Match Charting Project (MCP) I initially questioned the value of the Parallel Sets visualization; MCP data includes a great deal more shot detail, but it doesn't include shot coordinates, and only a rough estimation of shot placement can be derived (more about this in a future post). But recently I was inspired to connect the Parallel Sets "Shot Explorer" visualization with the Points-to-Set graphic via "Point Highlighting". The result is that when a collection of shots is selected in the "Shot Explorer" it is possible to view when during a match those shots occurred.


In Summary, Parallel Sets are a useful frequency-based representation of data. Tennis Matches generate a large, complex data set, and most of it is not amenable to time-series analysis. Using a frequency-based visualization in combination with time-series views makes it possible to create collections of data elements (Shots) and visualize their distribution throughout a Tennis Match.




































